We Benchmarked AI Models on Architecture Diagrams at Scale

TL;DR
Architecture diagrams are where critical security decisions live. As AI-driven development accelerates, understanding these diagrams at scale becomes essential for design-stage security. We benchmarked leading AI models on their ability to extract structure from real, large architecture diagrams and found that general-purpose LLMs collapse rapidly beyond 30-40 components, exactly where real-world systems begin. They treat diagrams as visual artifacts to describe, not systems to model. Prime maintained 95-100% accuracy even at 150+ nodes by solving a fundamentally different problem: building structured representations instead of interpreting images. This isn't incremental improvement, it's the difference between a system that describes what it sees and one that actually understands large, complex architectures.
In the age of AI-driven development, architecture matters more than ever. Prompts don't change individual lines of code, they change how systems are composed, connected, and allowed to interact. But to change an architecture, you first need to understand what already exists.
In most organizations, that understanding lives in architecture diagrams across tools like Lucid, Draw.io, Miro, and other diagramming platforms.
We benchmarked leading AI models on their ability to understand these diagrams at scale and found that while general-purpose models work on small systems, they break down quickly as complexity grows. Prime maintained accurate system-level understanding even on large, complex architectures, highlighting the difference between describing diagrams and reasoning about real systems.
Why does architecture understanding matter for AI-driven development?
As software systems grow more distributed, interconnected, and automated, architecture has become the primary unit of change. Products are no longer shaped line by line, but by decisions about composition, interaction, and boundaries.
The core decisions that manifest in architecture include:
- How services are composed
- Where trust and responsibility boundaries exist
- Which components are allowed to communicate by default
- How data flows across the system
Once AI enters the development loop, many of these decisions stop being explicit. Choices about service boundaries, dependencies, and integration patterns are increasingly embedded inside prompts and generated artifacts, rather than surfaced through formal design discussions. In practice, the most durable record of those decisions lives in architecture diagrams across tools like Lucid, Draw.io, Miro, PowerPoint, and similar systems-diagrams that reflect how teams actually reason about structure, dependencies, and boundaries.
That leads to a very practical question: If AI systems are going to contribute to building modern software, can they reliably understand the architectures organizations already use to reason about change?
Where architecture diagram understanding breaks down
In practice, this is where teams start to run into problems.
Through our work at Prime with Security Architecture and Product Security teams, we repeatedly saw the same pattern. Uploading an architecture diagram into an LLM often appears to work at first. The model describes the system, names key components, and even infers a few flows.
But as diagrams grow in size or complexity, exactly where real production systems live, the output becomes unreliable:
- Components are missed or merged
- Relationships are dropped or misrepresented
- Trust boundaries disappear
- Critical structure is confidently simplified away
This wasn't a prompt issue, and it wasn't tied to any single model. We saw the same failure modes across teams, tools, and use cases. What broke wasn't the explanation, it was the model's ability to preserve system structure as complexity increased.
At that point, the question stopped being "can LLMs describe diagrams?" and became something more fundamental.
So we decided to measure it.
The experiment: How well can AI models understand architecture diagrams?
We designed a benchmark to test how well different AI systems can understand and extract structure from architecture diagrams.
Systems tested
We ran the experiment across multiple leading, state-of-the-art models, alongside improved methodologies we developed at Prime, using the same inputs and prompts.
What we measured
Two core capabilities:
Node accuracy – How accurately the model identifies and classifies components in the diagram
Edge accuracy – How accurately the model identifies relationships, flows, and connections between components
Edges are particularly important from a security perspective, since they represent data flows, trust boundaries, and potential attack paths.
Methodology
- We used architecture diagrams at increasing levels of complexity, ranging from small diagrams (~15 nodes) to large diagrams (~150 nodes and ~160 edges)
- Each test was run three times per model, averaging the results
- Inputs were high-resolution PNG images generated using draw.io
- Prompts were kept consistent across runs to eliminate prompt bias
- The same diagrams and prompts were used for all models
Can AI models accurately extract components from architecture diagrams?
Node accuracy results
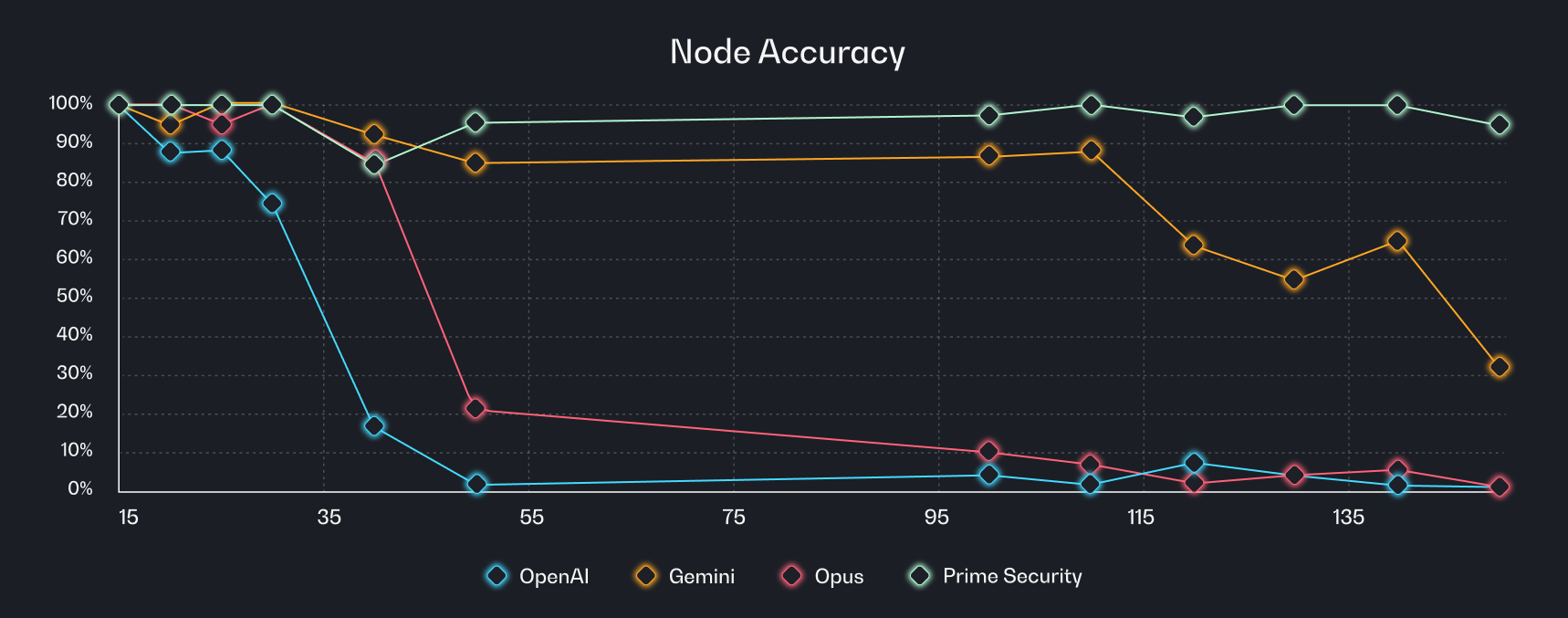
All models performed well on small diagrams. The problems appeared quickly as scale increased:
- Once diagrams exceeded roughly 30-40 nodes, general-purpose models began to degrade rapidly
- Accuracy collapsed entirely for some models by ~50 nodes
- Prime maintained ~95–100% accuracy even at 150+ nodes
The degradation wasn't gradual decline, it was structural collapse. Models that correctly identified 95% of components in a 20-node diagram would miss or merge half the components in a 60-node system.
Can AI models accurately identify relationships in complex architectures?
Edge accuracy results
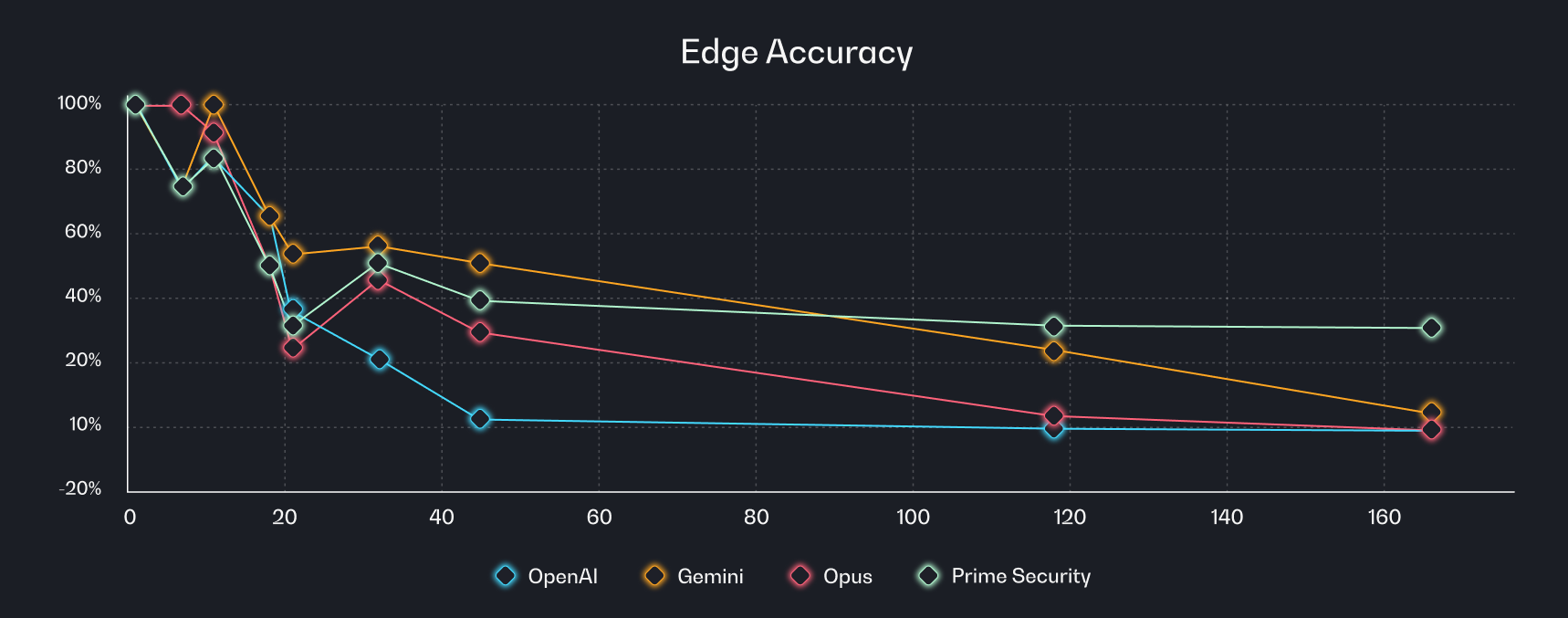
Edge extraction proved significantly harder for every system, and this is where the real problem lives.
- General-purpose models showed steep degradation as edge count increased
- Some dropped to near-zero accuracy well before 100 edges
- Prime stabilized at consistent accuracy even at the highest complexity tested
This distinction matters: identifying components is useful, but understanding how those components interact is where security insight actually comes from. A model that can list every service in your architecture but cannot reliably map which services communicate, where data flows, or which boundaries matter is fundamentally unable to support threat modeling or design review at scale.
The gap between "can describe a diagram" and "can model a system" becomes obvious once relationships enter the picture.
What causes AI models to fail at architecture diagram understanding?
This experiment highlights a fundamental difference in how AI systems reason about architecture.
General-purpose LLMs treat diagrams primarily as visual artifacts. They interpret, summarize, and compress what they see in a single pass. As complexity increases, they lose global consistency: entities blur together, long-range relationships drop out, and structural fidelity gives way to approximation.
This isn't a limitation of model intelligence, it's a structural constraint of the approach. Vision-language models are optimized to describe images, not to extract formal representations of systems. When you ask them to process a 150-node architecture diagram, they're doing visual interpretation at every step. There's no mechanism to maintain global consistency as local complexity increases.
Rather than processing a diagram in a single pass, Prime uses a multi-stage extraction pipeline that first builds a structured representation of components and containers, then separately resolves relationships and flows. This allows the system to maintain global consistency even as local complexity increases.
In short: most models are diagram readers. Prime is a system modeler.
Why accurate architecture understanding matters for threat modeling
This distinction matters because architecture understanding is not an academic exercise.
Teams increasingly need AI systems that can reason about architectures before code exists, across hundreds of concurrent initiatives, and without losing consistency as development velocity increases. If a system cannot preserve architectural structure beyond small diagrams, it cannot reliably support design-stage reasoning at scale.
Consider what breaks when architecture understanding fails:
- Threat models miss critical data flows because the model dropped edges
- Security reviews produce inconsistent guidance on similar architectures
- Risk assessments fail to account for trust boundaries that weren't extracted
- Teams lose confidence in AI-assisted analysis and revert to manual review
At 30% - 50% accuracy, automated threat modeling isn't just less useful, it's actively harmful. Engineers stop trusting security guidance, and security teams spend more time debugging bad outputs than they save from automation.
Conclusion: What it takes to understand architecture at scale
The takeaway is not that LLMs are "bad at diagrams." It's that understanding architecture requires persistent, structured system reasoning, not just visual interpretation.
Most AI systems were built to interpret and describe. Prime was built to model and reason. This experiment makes that difference measurable.
The challenge wasn't incremental, it required rethinking how architectural understanding works. General-purpose models will continue to improve at visual interpretation, but the structural problem remains: treating diagrams as images to describe rather than systems to model means accuracy collapses as complexity grows.
Prime solved this by building extraction pipelines that preserve structure first, then resolve relationships within that structure. The result is consistent accuracy on large, complex diagrams at scales where other approaches break down entirely.
For organizations adopting AI-driven development or trying to scale threat modeling and security design reviews, this matters immediately. The architecture diagrams you already use to reason about systems need to be something AI can reliably understand, not approximately, but structurally. Otherwise, design-stage security remains bottlenecked by manual review, and the gap between development velocity and security coverage continues to widen.
We didn't benchmark architecture diagram understanding to show that Prime is better at reading images. We did it to demonstrate that understanding architecture at scale requires fundamentally different approaches, and that those approaches now exist.